.jpg&blockId=c274d3f5-f892-4f17-a6c1-7cdf71224491)

.jpg&blockId=c274d3f5-f892-4f17-a6c1-7cdf71224491&width=256)
Facilitate Your Life, FYLs
 About me
About me

Blog
Gallery
Search







Intro : 소마를 마무리하며
작년 소프트웨어 마에스토로 11기를 마치고 회고를 작성하지도 않았으면서 지금와서 무슨 회골까 싶지만, 사실상 회사 업무가 소마의 연장선이기도 했고 첫 직장생활에서의 경험을 글로 작성해야 할 것 같아서 이렇게 남기게 되었다. (물론, 생각보다 인수인계가 일찍 끝나서 시간이 남게된 것도 영향이 크다 ~_~)
1학년 때, 대학교 공지글에 인턴 관련 내용이 있어서 바로 지원을 하고 최종합격까지 했었는데, 1학년이라는 이유로 처우협의 중 사전에 공지된 내용보다 금액을 많이 깎기도 하였고(?) 주말근무까지 해야한다는 이야기를 듣고 인턴을 포기했던 경험이 있다. 이 때 이후로 '아 그때 그래도 그냥 인턴 경험이나 해볼껄'하는 아쉬움도 있었고, 그 때문에 2학년 이후로는 실제 회사에서의 업무를 해보고 싶다는 생각이 매우 크게 들었다.
그리고 2학년때 우연히도 소프트웨어 마에스트로에 합격하게 되었고, 이 때 개인적인 목표로 소마가 끝나면 바로 인턴을 지원할 수 있을 정도로 실력을 쌓기 위해 ML Engineering에 대해서 다양한 것들을 시도하고자 하였다. AWS Lambda를 이용해서 서버리스로 ML서빙을 구현하기도 했고, TorchServe, TFServing등 잘 패킹된 라이브러리들로 만든 모델을 서빙해보기도 했었다. 또한, 소마 자율멘토링때 죽도록 들었던 쿠버네티스를 직접 써보고 싶어서 AWS EKS로 이것저것 가지고 놀아보기도 했고, Message Queue의 요청량에 따라서 자동으로 Node와 Pod를 늘이고 줄이는 아키텍처를 실제로 구현해보기도 했다.(쏘카 블로그가 많은 도움이 되었다..! : https://tech.socarcorp.kr/data/2020/03/10/ml-model-serving.html) 주제가 주제인터라 실시간으로 피아노의 소리를 듣고 어떤 음인지 맞추는것도 구현하기 위해 On-Device ML도 구현해보았다. 이런 경험을 소마 보고서에 녹여낼 수 있었고, 능력자들인 프론트엔드를 맡아준 인성이형과 백엔드를 맡아준 하균형 덕분에 Banju앱을 실제 사용 가능한 MVP로 완성시킬 수 있었다. 사실 소마를 시작할때는 "내 실력에 무슨 인증이얏...!" 하고 인증은 꿈도 못꾸고 (주변에 무서운 팀들이 많더라...) 내가 좋아하는거나 완성시키고자 했었는데, 의외로 심사평이 매우 좋았고, 덕분에 소마 11기 인증까지 받게 되었다.
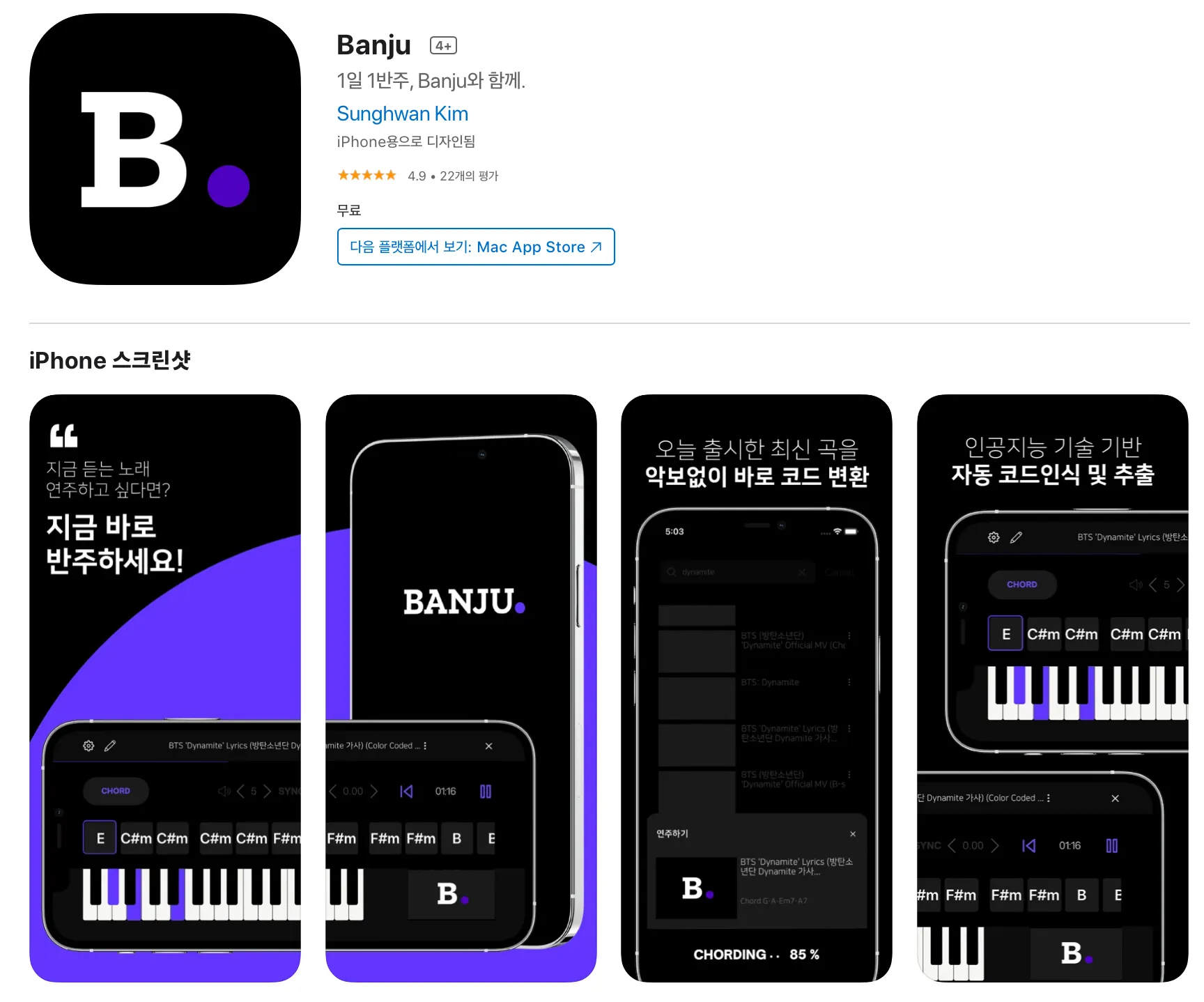
Banju가 AppStore에 올라간 모습.
소마는 재밌었고, 그 안에서 만났던 다른 연수생이나 멘토님들 한분한분이 소중했다. 그리고, 소마가 끝날무렵 나는 처음에 목표로 했었던 실제 회사에서의 인턴생활을 해보고 싶어 회사들을 알아보았고, 마침 프로그래머스 윈터캠프가 그때 진행되어 회사 5군데를 지원하게 되었다. 그중 4개는 ML리서치 관련된 직군으로 지원을 했었고, 나머지 1개는 지금까지 다녔던 가우디오랩을 지원하게 되었다. 특이했던건, 가우디오랩이 채용하고 있던 직군은 ML직군이 아닌, Vue를 스택으로 하는 Front-End 직군이었던 것이다.
첫 직장, 가우디오랩에서의 8개월
2021/07/22 01:39
회고
모바일
ML Engineer
<Copyright 2024. Daniel Kim's Dev Blog. All right reserved.>