.jpg&blockId=c274d3f5-f892-4f17-a6c1-7cdf71224491)

현재 오피스 책상, 하임캠프 25차 찬양팀 리더가 직접 작성해준 가사
개요
벌써 회고 날이다. 2022년은 코로나 팬데믹 이후로 드디어 외부 활동을 늘릴 수 있었던 시기였어서 정말 재미있던 일들이 많았던 것 같다. 개인적으로 만족하는 점들도 많았던 해이고, 아쉬웠던 점들도 좀 많았던 해였던 것 같다.
이번 회고도 올해 동안 어떤 일들을 진행했는지, 그리고 다른 일들은 어떤 게 있었는지 개인적으로 정리하는 목적으로 작성해보고, 내년에는 어떻게 살아갈지 간단하게 목표를 세워보려 한다.
What I did…
Working as a ML Engineer
벌써 가우디오랩에서 스캐터랩으로 넘어온 지도 1년이 조금 넘었다. 작년에는 온보딩과 함께 사내 ML 인프라 개선에 힘을 쏟았다면, 올해는 ML Pipelining 관련 일들을 많이 수행했었다. 많이들 이야기하는 “MLOps”를 제대로 해보고 싶다는 욕심이 컸던 것 같다. 1) ML Production Life cycle에서 구성원 간 커뮤니케이션 코스트를 줄이고, 2) 최대한 사람의 개입을 줄이면서 ML 모델이 학습되고 배포되기까지의 자동화를 하는 것에 대해 생각하는 게 재밌고, 사내 통합 ML 플랫폼을 구축하겠다는 미래를 보면서 달려왔기에 업무도 자연스럽게 그쪽으로 많이 진행했던 것 같다.
Apache Beam 도입, 그리고 비식별화 파이프라인
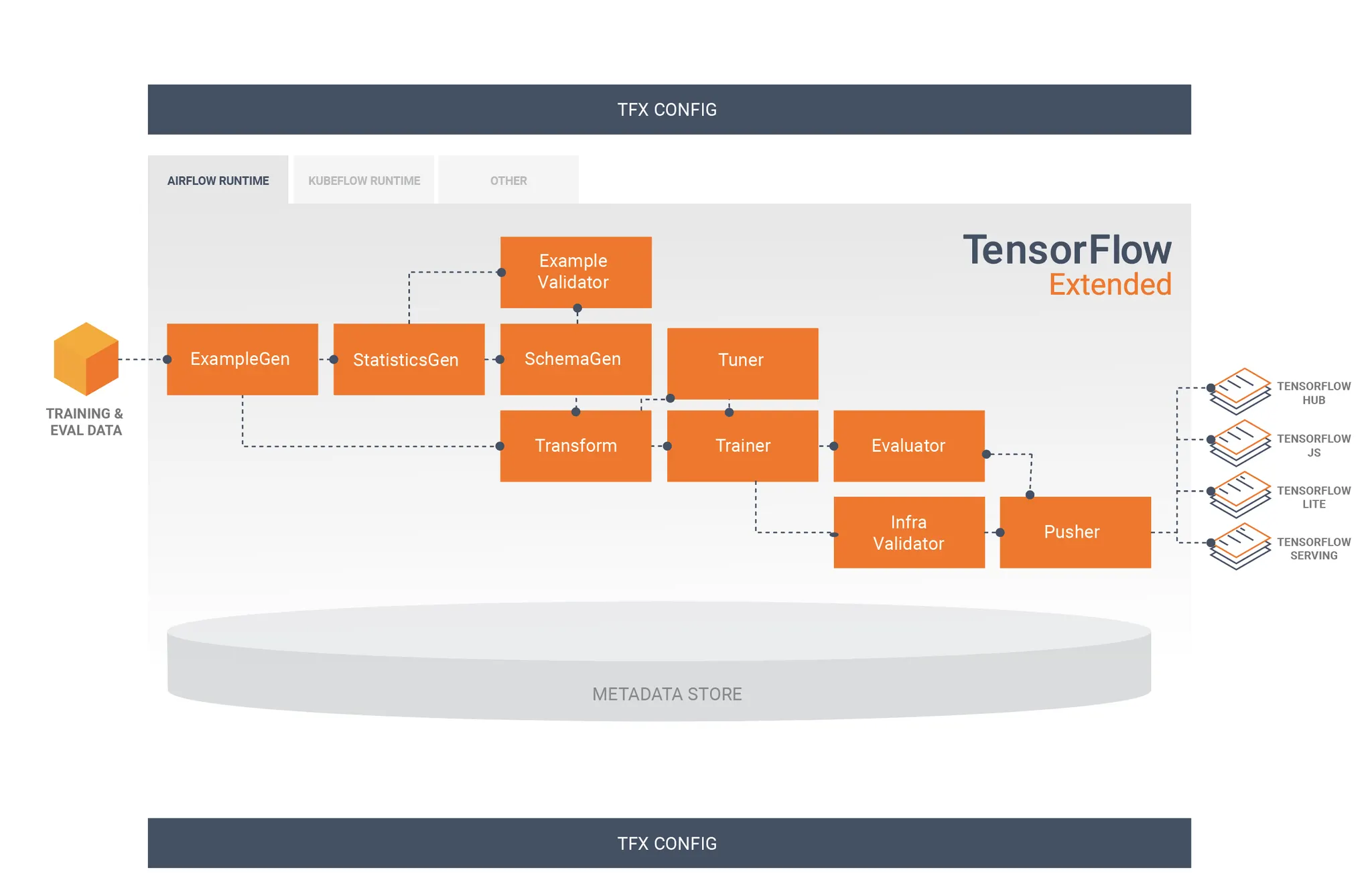
TFX의 Component간 상호작용, https://www.tensorflow.org/tfx/guide
사실 Apache Beam에 대해 원래 큰 관심은 없었는데, ML Pipelining 솔루션에서 나름 선두 주자를 달리고 있는 TFX(TensorFlow eXtended)에서 Apache Beam을 Backend로 하고 있기도 했고, 올해 초에 유닛 리드인 승환님이 Apache Beam에 대해서 이런저런 이야기를 해주셔서 관심을 가지게 되었다. 당시 Hadoop 기반의 데이터 파이프라인 솔루션들(MapReduce, Spark, Flink…)에 대해서도 사용해본 적이 없었고, 심지어 데이터 웨어하우스 솔루션들 (BigQuery, Redshift, ….)들도 사용해보지 못했을 정도로 데이터 엔지니어링에 대해선 완전 뉴비였었다.
그렇지만, Apache Beam을 공부하다 보니 정말 매력적인 Framework라는 것을 느낄 수 있었다. 처음 입문할 때는 “Write Once, Run Anywhere”라는 Apache Beam의 철학에 큰 매력을 느꼈다. Batch Pipeline과 Streaming Pipeline을 하나의 코드로 작성할 수 있다는 점은 둘째치고, 일단 동일한 코드를 Local 환경과 Container 환경, 그리고 GCP의 Serverless Apache Beam Runner 서비스인 Dataflow 환경에 바로 실행할 수 있다는 것이 너무 좋았다. 당시 사내의 ML 용 Data Pipeline들은 Kubeflow Pipelines로 작성이 되어있었는데, Kubeflow Pipelines는 실행 한번 해보려면 Docker Image들 말고, Pipeline 만들고, Kubeflow 배포하고, 거기에서 또 실행까지 하는 모든 과정이 너무 불편해서 Apache Beam의 장점이 더욱 도드라지게 느껴졌던 것 같다.
Apache Beam으로 수행한 주 업무는 사내의 Kubeflow 기반 비식별화 파이프라인을 Apache Beam으로 마이그레이션 하는 일이었다. 대화 데이터의 가명 처리는 일반적인 Tabular 데이터의 가명 처리와 달리 Regex 처리나 이름 치환 등 복잡한 로직들이 있고, 가명 처리의 논리를 지키기 위해 필요한 복잡한 처리 과정이 있었다. 그렇기에 Apache Beam 위에서 Faiss Vector Search를 진행한다든지, ML Model Inference를 수행하는 등 Apache Beam에 대해 ML Engineer의 입장에서 더욱 깊숙이 파헤쳐볼 수 있었다.
하지만, 제대로된 스터디 없이 파이프라인을 작성하다 보니 파이프라인의 구조화나 배포와 관련해서 약간 어설픈 면이 있었다. 또한, Apache Beam을 직접 도입해보면서 단순히 사내의 ETL Pipeline들에만 적용할 것이 아니라, 사내 리서쳐 엔지니어 모두가 사용할 수 있겠다는 생각이 들었다. 각 프로젝트에서 Multiprocessing 기반 유지보수도 잘 안되는 일회성 파이프라인을 각자 만들고 이를 실행하기 위한 머신도 따로 준비하는 것이 아니라, 리서쳐/엔지니어가 수행하고 싶은 전처리 로직만 작성한 다음, GCP Dataflow에게 나머지 모든 것을 맡기는 형태가 매우 아름답지 않나 하는 생각이 있었다. 그래서 4월쯤에 사내 Apache Beam 스터디를 열었고, 10명의 구성원이 3개월 동안 Apache Beam의 기본적인 부분들을 익힐 수 있었다. 그 결과 사내의 많은 프로젝트에서 실제로 Apache Beam을 현업에 도입하는 케이스들을 많이 볼 수 있었다. 나름 사내에서 직접 열어보는 첫 스터디있기도 했고, 실제로 스터디가 각자의 현업에 도입되는 것을 지켜보니 아주 뿌듯했었다. 현재는 사내에서 Apache Beam을 주기적 비식별화 파이프라인, 학습을 위한 데이터 전처리 파이프라인, 레이블링을 위한 샘플링 파이프라인 등 정말 수많은 곳에서 사용 중에 있다.
아무래도 Apache Beam 관련 업무들을 많이 수행하다 보니 블로그 거리들도 많이 생겼고, 함께 도입한 승환 님과 함께 총 세 편의 블로그를 작성하였다. 1편은 Apache Beam을 도입하면서 했던 고민거리들을, 2편은 실제로 Apache Beam으로 파이프라인을 구축하면서 생겼던 개발 관점의 고민거리들을, 3편은 Apache Beam에서 Native 하게 지원하는 MLInference와 관련된 이야기들을 풀었다. 좀 기분 좋았던 것은 TFKR/MLOpsKR에서 Google 사내로도 퍼졌는지 Apache Beam 공식 트위터에 작성한 블로그가 태그되기도 하였고, Beam Maintainer중 한 명으로부터 메일을 받기도 하였다. 마침 Beam Summit 2022가 얼마 남지 않은 시기여서 “아 우리 미국 가는 거 아니에요??” 하고 설레발을 치기도 했지만, 결국에 설레발로 끝나게 되었다.  조금 더 강력하게 어필했었음 좋았지 않을까 하는 후회가 생겼었다.
조금 더 강력하게 어필했었음 좋았지 않을까 하는 후회가 생겼었다.
조금 더 강력하게 어필했었음 좋았지 않을까 하는 후회가 생겼었다.





Model Serving Infrastructure : A/B Test 구축 및 인프라 최적화
루다가 올해 다시 세상 밖으로 나왔다. 사람들이 루다와 대화하기 시작하였다. 대화 경험을 향상시키기 위해 사내에서는 꾸준히 새로운 대화 모델들이 개발되었다. 새로 만든 모델을 Production에 배포하기 위해서는 모델의 평가가 이루어져야 하는데, 다른 일반적인 ML 모델과는 달리 대화 모델은 정량적인 지표로 대화 성능을 평가하기가 어렵다. 물론 수많은 정량 지표들은 존재한다. 하지만, 정량 지표가 높다고 해서 무조건 ‘재밌는 대화’, 또는 ‘루다와 가까워질 수 있는 대화’가 이루어지는 것은 아니다. 물론, 내부에서도 대화 성능의 평가를 위해 정성평가도 따로 진행하기는 하지만, 결국에 대화 모델은 루다를 사용하는 다수의 사용자에게 배포되는 것이기 때문에 해당 정성평가 결과도 100% 신뢰할 수는 없다. 그래서, 루다도 다른 서비스들과 마찬가지로 서비스의 만족도를 평가할 수 있는 가장 좋은 지표인 리텐션을 보기 위해 A/B Test와 관련된 프로젝트가 열렸다.
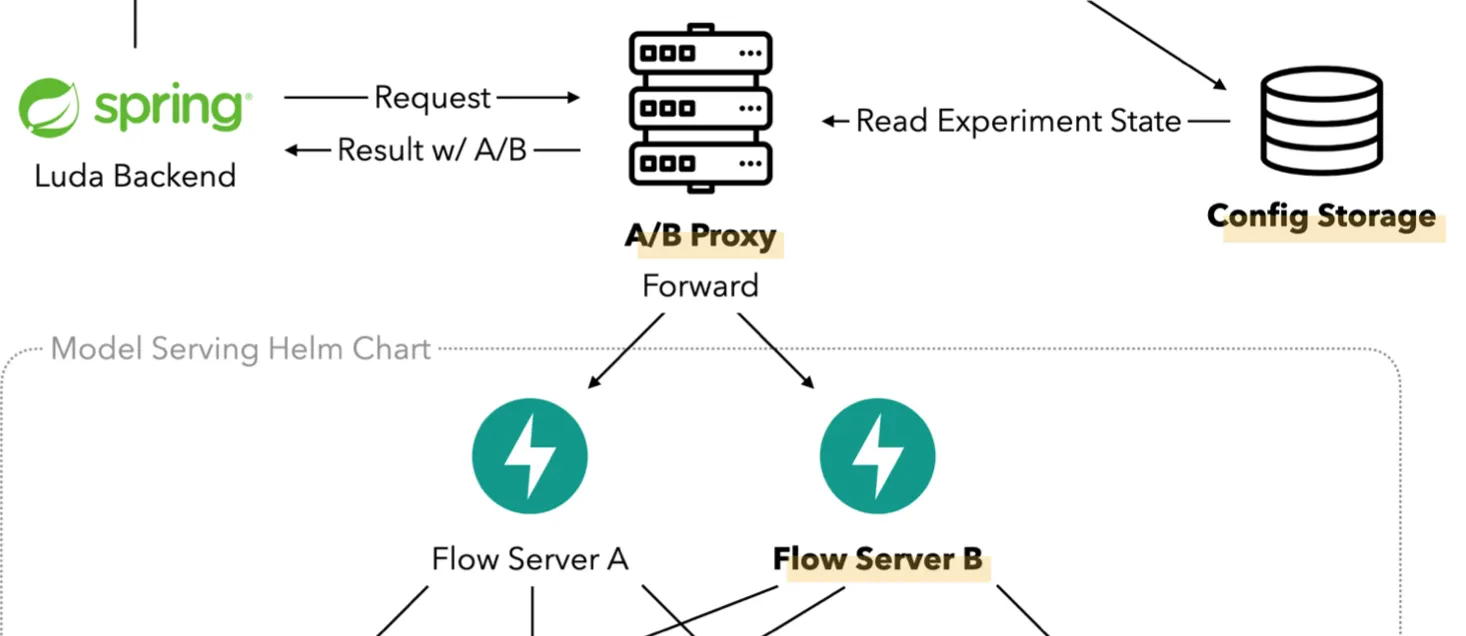
Scatterlab MLOps Meetup 2022에서 발표된 A/B Test Infra 구성도, 여기서 Flow Server는 Dialog Server로 이름이 변경되었다.
곧 자세한 내용은 회사 블로그에 작성될 예정인데, 루다 제품의 비즈니스 로직을 담당하는 서버와 루다의 대화를 담당하는 서버 간의 Coupling을 최대한 없애기 위해 인프라 단에서 A/B Test를 수행할 수 있도록 설계가 되었다. 간단히 설명을 해보자면, 루다와 대화할 수 있는 여러 개의 대화 서버(Dialog Server)들이 있고, 그 대화 서버들에 요청을 분배해 주는 서버인 A/B Proxy 서버를 구성하는 방식으로 설계가 되었다. 같은 유저는 같은 모델로 라우팅이 될 수 있도록 랜덤하게 서버를 지정해주는 Randomizer 로직이 A/B Proxy 서버에 구현되어 있다.
설계된 A/B Infra를 실제로 구현하기 위해 다양한 일들을 해볼 수 있었다. A/B Proxy 구현에 가장 적절한 언어를 찾아보기 위해 Golang 기반의 서버와 FastAPI 기반의 서버를 작성하여 부하 테스트를 해보기도 하였고, Kubernetes의 ConfigMap을 Watch하여 별도의 스토리지 서버 없이 A/B Routing 정보를 A/B Proxy 서버에 흘려보내도록 구현해보기도 하였다. 최종적으로 A/B Test를 수행하는 인프라를 배포하기 위해 여러 Helm Chart 구조를 설계해보기도 하였고, 팀원분의 제안에 따라 ArgoCD의 Application 안에서 또 다른 Application을 배포할 수 있는 App of Apps Pattern으로 배포해보기도 하였다. 이렇게 만든 인프라는 실제로 루다 정식출시 전에 새롭게 개발된 컴포넌트들인 생성모델(Luda Gen 1)이나, 이미지 커멘팅 모델(Photo Chat) 등의 사용자 반응을 측정하기 위해 사용되었다.
A/B Test Infra도 중요하지만, 모델의 배포에 있어서 가장 중요한 것은 역시 비용 최적화이다. 루다를 구성하는 모델들에는 생성모델과 같이 굉장히 무거운 모델들도 있고, 그 종류도 다양하기 때문에 각 모델 서버를 배포할 수 있는 최적의 Framework도 찾아야 하고, 인프라 단에서 효율적으로 Scaling할 수 있도록 모델 서버의 RPS(Request per Second)를 측정해야 했다. 기존에 배포되던 모델은 이전 프로젝트에서 Inferentia나 FasterTransformer 등으로 최적화가 되어서 참고할 자료가 많았는데, 그 덕분에 막힘없이 새로 배포되는 모델들을 최적화하기 위한 선택지들을 확장하기가 굉장히 용이하였다.
생성 모델 서빙은 FriendliAI의 ‘Orca’라는 Product를 도입하면서 비용을 크게 줄일 수 있었다. 기존에 다른 Framework들을 사용해서 배포했을 때보다 Orca를 도입했을 때의 성능을 보고 굉장히 놀라기도 하였다. 함께 프로젝트를 진행하던 준성 님도 신기했었는지 바로 CUDA 스터디를 열었었고, 함께 스터디를 진행하며 2~3개월정도 CUDA의 기본적인 내용들을 터득할 수 있었다. 아직 학부 졸업을 안 한 터라 멀티코어나 병렬 프로그래밍 등의 수업을 듣지는 않았는데, CUDA의 내부적인 로직을 보니 좀 재미있었다.
What’s Next, 궁극적인 Continual Learning을 향하여…

대화 모델의 Continual Learning을 왜 해야하는가? (Scatterlab MLOps Meetup 2022 자료)
지금까지 사내의 ML Infra를 개선하고, Apache Beam 기반의 다양한 파이프라인들도 작성하고, 모델 배포를 위한 인프라 설계 등등을 진행했었지만, 사실 이 모든 것의 커다란 축은 항상 CL(Continual Learning)의 구현에 있다고 생각하면서 업무를 진행해왔다. 물론, 현재도 루다는 꾸준히 새로운 데이터를 배우고 있다. 사람들과 대화하며 모델의 성능은 꾸준히 발전하고 있는데, 나는 이를 단순히 개발자의 영역에서만 그치는 것이 아니라, 사내의 기획자들이나 루다의 성능을 개선하고 싶은 사내의 어떤 사람이든 수행할 수 있는 시스템으로까지 발전시키고 싶다. 올해에도 여러 CL 프로젝트를 진행해왔고, 내년에도 꾸준히 CL 관련 프로젝트에 참여할 예정이다. 내년에 회고를 쓸때 오늘의 회고를 돌아보며 현재 생각하는 목표까지 도달했으면 하는 소망이 있다.
Competitions
작년에 대회 때문에 아쉬웠던 마음이 컸었는데, 올해는 그 아쉬움을 전부 해결해줄 정도로 정말 많은 대회들을 참여했었고, 성과들도 꽤 좋게 나왔던 것 같다. 시간 순서대로 나열하자면 아래와 같다.
Castanets: Azure Virtual Hackathon 장려상

Azure Virtual Hackathon은 Azure 인프라를 활용한 게임 개발 해커톤, Azure의 서비스들을 이용해 AI Product의 아이디어를 제시하는 아이디어톤, 그리고 업무환경을 크게 개선할 수 있는 GitHub Actions를 만드는 DevOps 해커톤으로 총 3개의 부문으로 대회가 진행되었다. 마침 사내에서도 Continual Learning을 위한 학습 프로세스를 담당할 수 있는 Process Manager의 개발이 필요했는데, 나가기 적절하겠다는 판단이 들어 함께 개발하던 승환 님을 불러서 대회에 출전하였다.
핵심은 Continual Learning에서의 Human-in-the-Loop, 즉 사람이 프로세스에 개입하는 상황에서 각 단계 사이에 리뷰 프로세스를 추가해주는 Action을 개발하는 것이었는데, GitHub Marketplace에 Azure를 활용할 수 있는 수많은 Action 들이 존재하여 손쉽게 개발할 수 있었던 것 같다. 설계와 아이디어 구체화에 많은 도움을 준 승환 님께 감사한 마음이 크다.
아쉽게도 3위인 장려상에 그쳤지만, 3가지 부문 각각을 시상하는 것이 아닌 한 번에 시상하는 것이었고 나름 DevOps 부문에서는 1위를 했기 때문에 뿌듯하였다. 비슷한 해커톤(아마… 네이버 웨일 Extension 해커톤)을 갓 대학생이 되었을 때 나간 적이 있었는데, 그 당시와 비교하였을 때 많이 성장했음을 느꼈고, 함께 대회를 나간 (해커톤 장인! ) 승환 님께 어떻게 해야 먹음직스러운 아이디어를 낼 수 있을지 많이 배웠던 것 같다.
) 승환 님께 어떻게 해야 먹음직스러운 아이디어를 낼 수 있을지 많이 배웠던 것 같다.(이 아이디어를 생각할 당시 먹고있던 버거가 성수동에 위치한 Castanets 버거였어서 이를 기념하고자(?) 팀명을 지었다! )
)Parrots: JUNCTION ASIA 2022 Track Winner

정션에 처음 나가봤다. 정션도 처음이지만, 이런 대규모 오프라인 해커톤은 처음 나가보았던 것 같다. 서로 모여서 뚝딱뚝딱 만드는 그 분위기를 느껴보고 싶었던 것이 참여 이유 1순위였다. 2순위는 기존에 해커톤을 많이 뛰던 팀원분들과 함께 팀을 이루면 어떤 시너지가 나는지 눈으로 직접 보고 싶었던 것도 있었다.
우리 팀은 기획자 없이 4인 개발자, 1인 디자이너(이긴 한데 사실 개발자! ㅋㅋㅋ) 팀으로 구성하여서 나갔다. 주제를 정하는 과정에서 고민이 많았는데, 최종 트랙은 블록체인 분야의 Chainapsis 트랙으로 결정하였다. 영향력은 모르겠는데, 다른 트랙보다 조금 마음에 와닿는(?) 아이디어링을 할 수 있을 것 같았다. 각자 많은 아이디어를 냈었는데, 아이디어를 고민하면서 정말 해결하기 어려운 질문들이 쏟아졌었다. “이럴 거면 DB를 쓰지 왜 블록체인을 쓰지?”, “본인을 인증하는 수단으로 블록체인을 이용하게 된다면 결국에는 중앙화된 인증기관이 있어야 하는데, 그러면 블록체인이 무슨 의미지?”, “블록체인 이용으로 발생하는 Gas나 Fee는 어떤 수단으로 사용자에게 지불하도록 유도하지?” 등 아이디어를 낼 때마다 위 질문들로 인해 <블록체인 기반 이력서 검증 서비스>나, <블록체인 기반 암표 없는 티켓팅 서비스> 등등 대부분의 아이디어가 기각되었었다.

JUNCTION ASIA 2022에서 제출한 키노트 자료중 일부. 이 페이지를 처음 봤을 때 가슴 한 구석에 약간의 웅장함이 있었다.
나는 원래 음악과 관련된 아이디어를 내는 것을 좋아했어서 작곡 협업과 관련된 아이디어를 던졌었다. 물론 해당 아이디어 역시 위 질문들이 막히게 되어 처음에는 기각이 되었었다. 계속 고민해도 뾰족한 아이디어가 떠오르지 않아서 Chainapsis 부스로 가서 아이디어에 대한 검증을 부탁드렸다. 그 때 들은 말이 인상 깊었는데, “블록체인 기술의 핵심은 각 개인의 지갑에 대한 사회적 Honority이다”라는 말을 듣고, 논의에 논의를 이어간 끝에 작곡 협업이라는 아이디어는 음악 협업을 위한 툴, 즉 음악 업계를 위한 Git을 만들면 어떨까하는 아이디어로 발전하게 되었다.
아이디어를 확정하고 나서 개발되는 속도는 정말 무서웠다. 아이디어를 정하기 전에 이미 로고는 튀어나왔고, 각종 페이지 디자인이 Figma로 순식간에 제작되었다. 제작된 디자인들은 Frontend를 담당했던 팀원이 정말 빠른 속도, 그리고 디자인과 정말 똑같게 개발해나갔다. 나는 Chainapsis에서 제공한 Cosmos SDK를 이용해 Chain 개발을 담당했는데, 문서를 이해하는데 좀 시간이 많이 걸려서 개인적으로 많은 답답함이 있었다. 시간이 지나고 CRUD 하나를 완성하고 나서는, 이후 과정들은 원활하게 진행할 수 있었다.
밤을 새우고 자료와 레포를 제출하고 나서 굉장히 홀가분하기도 했고, 결과가 기대가 되었다. 주변을 둘러보니 다들 잠을 제대로 못잔 상태였는데, 거기서 오는 나름의 우중충한(?) 분위기도 좋았다! 결과는 각 테이블에서 Chainapsis 관계자분들께 발표를 진행하고 나서 한참 지나서 났는데, 첫 해커톤에서 Track Winner가 될 줄은 상상도 못 했다. 물론 Final Winner까지 가지는 못했지만, 나름 Final Winner도 우리 회사에서 함께 출전한 팀이 받게 되어서 오히려 기분이 좋았다! (너무 아쉽기도 했다 ㅋㅋㅋ)
내년에도 정션과 같은 오프라인 해커톤은 꼭 다시 나가고 싶은데… 이번에 아쉬웠던 부분들을 모두 해소하고 싶다. 1) 조금 더 음악과 관련된 아이디어로 우승을 해보고 싶고, 2) 팀 내에서 조금 더 눈에 보이는 부분들을 기여하고 싶으며, 3) 영어로 발표하고 싶다! 함께 나갈 분을 찾습니다
PIDICON 2022: 과기정통부장관상

PIDICON 2022, <개인정보 가명·익명처리 기술 경진대회>는 주최 측에서 제공한 재현 데이터를 바탕으로 가명처리 및 익명처리를 직접 진행하는 온라인 해커톤이다. 사내에서 한 분이 이거 나가보면 어떻겠냐고 슬랙에 올렸었는데, 나름 올해 대화 비식별화 파이프라인을 만들기도 했고 가명처리 프로세스에 대해서 조금 더 몸으로 익히고 싶던 마음도 있어서 바로 참여해겠다고 의사를 표현했다. 마침 사내에 개인정보 관리사 자격증을 딴지 얼마 안된 두 분이 있었는데, 한 분은 아쉽게도 대회 날짜와 훈련소 날짜가 동일하여서 대회에 출전할 수 없었다. 그렇게 해서 남은 4명이 모여서 팀을 꾸려 대회에 출전하게 되었다.
예선은 주어진 쇼핑몰 데이터를 익명처리하는 과제가 주어졌고, 본선은 노동부 데이터를 의료기관에 전달하는 상황을 가정했을 때의 가명처리 및 익명처리를 진행하는 과제가 주어졌다. 예선때는 대회 주최측에서 제공하는 ARX라는 툴을 계속 활용해봤는데, 익숙하지 않은 툴이다 보니 해커톤 기간 내에 주어진 과제를 해결하기에는 좀 무리가 있어 후반부에 가서는 EDA 작업을 함께 진행했었다. 본선때는 예선때의 아픔(?)을 다시 겪지 않고자 전날에 급하게 Apache Beam 기반의 Tabular 데이터 익명처리 파이프라인을 만들어놓기도 하였고, 대회를 시작할 때 최대한 EDA 작업 및 아이디어링에 집중하였다.
생각보다 대회 자체는 그렇게 어려운 작업은 아니었는데, 다른 경진대회와는 달리 대회에서 보고자 하는 정량지표가 명확하게 제시되어있지 않아 정말 많은 논의를 했던 것 같다. 유용성과 안정성 사이에서 정말 많은 저울질을 했었는데, 결국에 이렇게 논의를 많이 했던 덕분에 대회 결과가 좋았던 것 같다. 나름 정부 기관에서 주최한 대회이다 보니, 상도 과기정통부 장관상이었는데, 소마 이후로 정말 오래간만에 받아보는 장관상이어서 기분이 더 좋았던 것 같다. 예선과 본선 모두 숙소를 빌려서 즐기면서 대회를 진행했는데, 정말 즐겁게 대회를 진행했던 것 같다.
기타 Side Jobs…
•
내/외부 발표로 사내에서 공개 세미나로 진행한 <2022 Scatterlab MLOps Meetup>과, 지인의 부탁으로 진행한 <AIFFEL MLOps 세미나>를 진행하였다. 이런 네트워킹 자리나, 발표할 수 있는 자리들을 굉장히 좋아하는데, 앞으로도 이런 발표기회들은 많이 만들고싶다.

•
올해 초에 비사이드(B-side)라는 사이드 프로젝트를 진행할 수 있는 프로그램에서 ‘산들산들’이라는 이름의 App을 개발했었다. 프론트엔드를 주로 업무로 진행하는 지인과 함께 가볍게 참여하였는데, 기획자 두 분, 디자이너 두 분, 프론트엔드 한 분과 백엔드 한 분이 팀으로 매칭되었다. 모르는 사람들과 함께하던 프로젝트다 보니 기획자가 아닌 입장에서 뭔가 음악을 주제로 하는 프로젝트를 강하게 밀어붙일 수가 없었다. 모두의 의견을 만족하는 등산앱으로 결정하였는데, 하다 보니 점점 커뮤니케이션의 빈도가 줄어들더니 결국 전체 앱을 완성할 수 없었다. 결국 본인도 흥미를 크게 느끼지 않던 분야이다 보니 자연스럽게 관심이 줄어들었긴 한데, 내년에는 제대로된 사이드 프로젝트를 성공시키고 싶다.
•
ML Serving Infra 최적화와 관련해서 외주를 진행했었다. 소마시절 한번 쓰고 당시에는 불필요해서 사용하지 않았던 Cortex라는 프레임워크를 사용하고 싶었기도 해서 덜컥 받아버렸는데, 역시 사이드 프로젝트가 목적이라면 아무리 현금이 동기부여를 해준다고 해도 책임이 부여되는 순간 재미가 없어지는 것 같다. 내년에는 하고 싶은 프로젝트가 있는데, 이번에는 분기 초에 직접 진행해보자…
취미, 일상, 그리고 다양한 이야기들…
일렉기타 꾸준히 배우기
작년에 이어서 올해도 일렉기타를 꾸준히 배웠다! 물론 그렇게 많은 시간은 쏟지 못해서 실력 향상이 엄청나게 되지는 못했지만, 여러 공연 및 예배에서 기타를 칠 기회를 가지게 되었다! 기타 너무 재밌다. 맥북으로 사운드메이킹도 해보고, 교회에서 빌린 POD 멀티이펙터도 열심히 연구해보았다. 많은 분들이 소리 너무 예쁘다고 피드백을 주셔서 더 재미를 느꼈던 것 같다.
맥북으로 사운드메이킹도 해보고, 교회에서 빌린 POD 멀티이펙터도 열심히 연구해보았다. 많은 분들이 소리 너무 예쁘다고 피드백을 주셔서 더 재미를 느꼈던 것 같다.헬스 PT

헬스를 엄청 끊었다. 우선 결과만 보면 현재까지 13kg 감량에는 성공했다. 현재 더 연장한 상태인데, 남은 기간동안 더 빡세게 해서 나머지 13kg도 감량에 성공시킬 예정이다…. (현재 정체기다 ㅠㅠㅠㅠ 맛있는게 너무 많아요..)
첫 회사 MLE 워크샵!!
작년에는 코로나로 인해 못갔던 워크샵을 드디어 갔다. 원래부터 좋은 사람들과 일하고 있다고 생각을 했었고, 그렇기에 그 이상으로 마음 편하고 정말 재밌게 갔다왔던 것 같다. 어쩌다보니 링크드인 비디오 썸네일의 주인공이 되었다 (…)
소중한 하임 공동체

2022년도 제24차 하임캠프와 제25차 하임캠프에서 찬양팀으로 섬겼다. 고등학교 시절 정말 바빴던 일상으로 본교회마저 못다니고 아침 일찍 다른 교회에 나가야 했고, 학교 내에서도 거의 유일한 마음의 쉼터였던 동아리였다. 그 마음에 매년 기회가 될때마다 섬기고 있다. 본 교회에서도 주로 세컨건반을 맡고있기 때문에 항상 찬양팀을 세컨건반으로 참여하고 있는데, 역시 세컨건반이 다른 악기보다 찬양 그 자체에 집중할 수 있어서 좋은 것 같다. 매년 본 교회 수련회보다 하임캠프에서 더 많은 은혜를 받고있는 것 같아 정말 감사함을 느끼고 있다! 내년 제26차 하임캠프 찬양팀 지원도 완료하였다! 올해는 개인보다도 조금 더 재학생들을 섬길 수 있도록 노력해봐야겠다…
올해는 개인보다도 조금 더 재학생들을 섬길 수 있도록 노력해봐야겠다…HAI, 이제 올해까지만…?

결국에… 올해도 HAI를 도와주었다. 회사가 학교랑 위치적으로 가까워지긴 해서 간간히 도와주러 갈 수는 있었지만, 일이 점점 바빠지기도 하고 시간도 잘 안맞아서 Fully-support까지는 해줄 수가 없었다. 그래도 1학년 때부터 함께했던 동아리가 없어지는 것은 지켜보고 싶지 않았고, 다행히 구성원중에 회장을 지원하겠다고 나서주셨던 분이 있어서 동아리를 유지시킬 수 있었다. 정말 회사를 다니는 입장에서 AI를 처음 접하는 학생들에게 해줄 수 있는 부분들은 최대한 지원하고자 노력하였다. 외부 연사자분들을 모셔서 커리어 세미나도 진행하기도 하였고, 회사에서 동아리에 지원할 수 있는 부분들은 전부 지원을 신청하였다. 2학기 프로젝트 발표 때는 회사 분들을 모셔서 프로젝트 멘토링을 진행하기도 하였다. 다행히 많은 동아리 구성원분들이 만족을 했던 것 같고, 내년도를 이끌어갈 풍성한 임원진도 구성할 수 있었다! 이제 마지막 인수인계를 거친 뒤 동아리 운영에는 손을 떼게 될 예정인데, 앞으로도 계속 동아리가 이어졌으면 하는 소망이 있다. HAI 화이팅!
결론
좋든 나쁘든 여러 일들이 많았다. 심지어 안 걸릴 줄 알았던 코로나도 걸렸던 해이다. 만족했던 일들도 많았지만, 아쉬웠던 부분들도 여러 가지가 있다. 이를 회고에 많이 활용한다는 KPT를 활용해서 정리해보려 한다.
•
Keep
◦
이것저것 도전하기: 해보고 싶은 것 다 도전했던 것 같다. 대회도 많이 나가고, 원하는 Framework도 사내에 직접 도입시키고, 피티도… 어떻게보면 도전이다. 내년도에도 지금 시점보다 더 넓은 시야를 가지고 싶다.
◦
Deep Dive: 하나의 Framework나 분야에 꽂히면 이를 완전히 내 것으로 만들고자 했다. 스터디도 열어보고, 블로그도 써보고, 이것 저것 많이 물어보면서 공부했던 것 같다.
◦
목표 지향적: 내년의 목표이기도 하지만, 올해도 회사에서 확고한 목표를 가지고 업무를 진행해왔다. 궁극적인 MLOps라 불릴 수 있는 Continual Learning을 위한 시스템을 구축하고 싶었으며, 이 목표 한 가지만으로 여러 일들에 대해서도 큰 의미 부여를 할 수 있었다.
•
Problem
◦
일하는 원동력은 (only?)흥미: 다른 회고 때도 언급되었던 내용인데, 사실 목표 지향적이고 일하는 원동력이 흥미인 것은 좋다. 그런데, 흥미가 떨어지게 된다면 순식간에 효율도 바닥을 찍는 경우가 여럿 있었다.
◦
자신감: 아직도 뭔가 강력하게 주장해야 할 내용이 있을 때 말하기 전에 먼저 위축되는 경우가 많았다. 이는 커뮤니케이션에 좀 커다란 문제들을 만들 때가 있었는데, 어떻게 보면 사람이 우유부단하게 만드는 경우가 많았다. 물론, 자신감만의 문제는 아니겠지만, 내년에는 조금 더 자신감을 가질 수 있었음 좋겠다.
◦
성장에 대한 오해: 지금까지는 뭔가 새로운 기술 도입하는 게 꼭 성장하는 것 같고, 그 외의 일들은 개인의 성장과는 거리가 멀다고 생각을 했던 것 같다. 그런데, 사실 업무를 진행하다 보면 신기술을 도입하는 것 말고도 주어진 문제를 조직에 가장 알맞은 형태를 고민하는 과정도 성장에 큰 도움이 된다는 것을 알게 되었다. 내년에는 올해의 경험이 성장의 발판이 되었음 하는 마음이 있다.
◦
작심한달(?): 가벼운 이야기로, 지금 운동 정체기이다. 다시 마음잡고 평소 잘 안하던 운동도… 꾸준히 했으면 하는 마음이 있다.
•
Try
◦
당장의 흥미보다 목표를 바라보기: 주변 사람들을 보면 굉장히 외부 영향에 덜 자극받고, 어떤 일을 하던 효율이 일정하게 나오는 사람들이 있다. 나도 Problem에서 언급했던 것처럼 단순히 흥미를 통해 업무의 동기부여를 하는 것이 아니라, 목표를 바라보면서 새로운 동기부여를 할 수 있었음 한다.
◦
자신감 향상을 위한 독서: 결국에는 어떤 주장을 할 때 자신감이 떨어지는 이유는 여러가지가 있다고 생각되는데, 나 자신이 해당 분야에 대해서 잘 알지 못한다는 데서 오는 불안감도 있고, 어떠한 이야기를 들었을 때 다양한 주장을 펼치는 능력을 길러본 적이 많지 않아서라고도 생각된다. 작년 목표로도 삼았지만… 올해는 약간의 위험의식을 느끼고 독서량을 늘렸으면 좋겠다.
◦
코드양 늘리기: 개인 프로젝트를 좀 늘리고 싶고, 오픈소스 기여도 해보고 싶다. 올해에도 사실 기여 포인트가 몇 가지 존재했지만, 다른 일들에 밀려 PR까지는 도달하지 못했던 것 같다. 올해는 1분기부터 개인 사이드플젝을 진행해봐야겠다!
◦
운동에 재미 붙이기: PT를 많이 받다 보니 이제 헬스장에 있는 대부분의 기구를 어떻게 사용하는지는 알게 되었다. 또 운동을 하면서 어떤 근육을 쓰고 있는지 정도는 알 수 있게 되었다. 이제는 재미를 붙일 차례이다.
2022년이 끝났다. 2023년에는 만 나이를 기본으로 쓴다길래 다시 20대 초반(22세)으로 돌아간다니 약간 기쁘다. 이상으로 2022년 회고를 마치려 한다! 내년에는 조금 더 많은 일들을, 조금 더 다양한 일들이 있었으면 좋겠다.